Code
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zipWe will explore how to efficiently batch large datasets with varied sequence length for training using infinibatch. The focus will be on solving multiple challenges associated with this and making it work with dataloader abstraction in pytorch library. Though our focus is on pytorch, Infinibatch is a pure python library agnostic of the deep learning library.
This post was inspired by this thread on twitter. > twitter: https://twitter.com/marian_nmt/status/1292850875715604480
We will use wikitext-103 dataset as an example. It’s a dataset with sentences from wikipedia. It has 103,227,021 word level tokens in it’s training split. It is used only for illustration, the techniques discussed here are can work for far larger dataset sizes.
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zipFor large datasets, loading the entire data into memory might not be possible. If we were to sample fully random batches we need to do random access on huge dataset. Depending on the disk latency this might be unfeasible.
To solve this we can do the following.
If we shard the pieces into too big chunks we might end up loosing statistical power in our training updates as we are essentially reducing the randomness of our samples used for training. But we can’t shard them too small either as that wouldn’t solve our disk access problem.
We need a flexible approach would make it easy to control how much data is to be loaded into memory for shuffling. To address this challenge in isolation, you can refer dataset sharding logic in NVIDIA’s MEGATRON language model training code. But infinibatch solves it in a more generalized manner along with our other challenges.
NLP datasets generally have samples which are of varied lengths. When we batch the data for training on devices like GPU, we are forced to make them into n-dimensional tensors with fixed dimension. The most common type of input for NLP models is of the shape Mini-batch size x Sequence length. The sequence length is either a fixed value or is the length of longest sequence in that batch. The shorter sequences in the minii-batch are generally padded with a padding token. These padding tokens are wasteful in terms of computation as they don’t do anything useful.
Some tutorials and examples you would find for pre-processing data would pad batches to a pre-determined sequence length independent of the elements in each batch. This is fully wasteful as many batches would have all the members less than the pre-determined length.
A better option would be to pad the elements of each batch to the sequence length which is maximum in that batch. This dynamic padding can improve efficiency but it doesn’t solve the entire problem. Let’s see why with an example.
Let’s implement a typical dynamic padding workflow with pytorch dataloader and a subword level tokenizer. We use BERT-base-cased tokenizer from huggingface’s transformers library. This tokenizes words to subwords. The BERT model was pre-trained with maximum subword length of 512. We can theoretically use sequence lengths larger than that but for our purposes we will leave it as such at 512.
We will use torch’s dataset and dataloader abstraction for this. It will as both an illustration of real world usage and is convinent as it helps avoid having to entire tokenized dataset in memory. We still have to load the sentences into memory once. This is not a problem for small datasets, but for very large corpuses it’s a big problem as mentioned before.
!pip install git+https://github.com/microsoft/infinibatch.git transformers torch
from typing import Dict, List
import torch
from torch.utils.data import Dataset, DataLoader
import tqdm
from transformers import AutoTokenizer, PreTrainedTokenizerFast
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import torch
%matplotlib inlineclass Wiki103(Dataset):
def __init__(self, tokenizer: PreTrainedTokenizerFast, data_path="wikitext-103-raw/wiki.train.raw", max_length: int = 512):
self.tokenizer = tokenizer
with open(data_path) as dp:
# We are
self.sentences = [sentence.strip() for sentence in dp if len(sentence.strip()) > 2]
self.max_length = max_length
def __len__(self):
return len(self.sentences)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return self.tokenizer(self.sentences[i], max_length=self.max_length, truncation=True)tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=True)
wiki_dataset = Wiki103(tokenizer=tokenizer)
sequence_lengths = []
for example in tqdm.tqdm(iter(wiki_dataset)):
sequence_lengths.append(len(example["input_ids"]))1164464it [04:25, 4380.35it/s]By plotting the truncated Subword sequence length vs Frequency we see a distribution with a large variance.
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=[7,5])
n, bins, patches = plt.hist(x=sequence_lengths, bins=50, color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Subword Sequence Length',fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.title('Sequence Length Distribution',fontsize=15)
plt.show()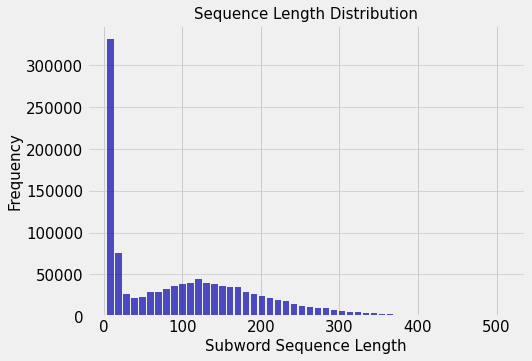
From the above graph we can intuit that if we draw random samples from the data to form a mini-batch, we would have few examples which are significantly longer than the rest. This would mean that we would add a lot of padding tokens. This holds even if we clean the very short length instances as noise.
Let’s implement dynamic padding and measure how much. We can use torch’s DataLoader abstraction to do efficient batching with multi-processing. Since our tokenized outputs are of different lengths we have to implement a collate function to pad them dynamically together. We can pass the tokenizer.pad function implemented in huggingface’s tokenizer as the collate function.
def collate_fn(examples: List[Dict[str, torch.Tensor]]) -> Dict[str, torch.Tensor]:
# Since huggingface has already implemented this, this function is just to illustrate what a collator does.
return tokenizer.pad(examples, return_tensors='pt')
dataloader = DataLoader(dataset=wiki_dataset, batch_size=32, collate_fn=collate_fn)Let’s assume that we can use maximum a batch size of 32 for max sequence length of 512 for our model in our training hardware without out-of-memory errors. The tokens per batch would be 512 * 32 = 16384. We can now compute how much of it is padding tokens and what is the distribution of the batch’s sequence length(which depends on the maximum element in the batch).
total_tokens = 0
padding_tokens = 0
batch_lengths = []
for batch in tqdm.tqdm(iter(dataloader)):
batched_input_ids = batch["input_ids"]
batch_lengths.append(batched_input_ids.shape[1])
total_tokens += batched_input_ids.numel()
padding_tokens += batched_input_ids[batched_input_ids == tokenizer.pad_token_id].numel()100%|██████████| 36390/36390 [06:04<00:00, 99.96it/s] print(f"Total Batches : {len(iter(dataloader))}")
print(f"Padding Tokens : {padding_tokens}")
print(f"Input Tokens : {total_tokens - padding_tokens}")
print(f"Total Tokens : {total_tokens}")
print(f"Padding Tokens % : {(padding_tokens*100)/total_tokens}")Total Batches : 36390
Padding Tokens : 244072396
Input Tokens : 119699332
Total Tokens : 363771728
Padding Tokens % : 67.09493267712108Surprise, surprise, 67% of our net tokens are padding tokens. This would imply that of all the computations that we do, only 33% of is done for useful work. This starkly highlights the problem with static batch lengths even when accounting for dynamic padding.
Let’s also plot the distribution of batch lengths.
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=[7,5])
n, bins, patches = plt.hist(x=batch_lengths, bins=50, color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Batch Sequence Length',fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.title('Static Batch - Dynamic Padding Length Distribution',fontsize=15)
plt.show()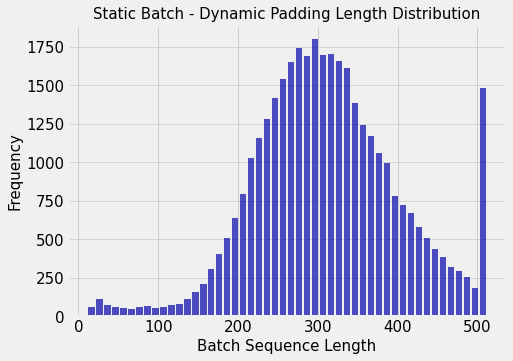
As batches are randomly sampled, we see a normal distribution as we can should expect by the Central Limit Theorem. The frequency in the final bin is deviant because we have a significant number of sentences which we had truncated, hence batches with them will have the maximum sequence length.
Instead of drawing samples in random, had we sorted our dataset by length, then we can form batches by packing similar length sequences together into a batch till we reach the maximum number of tokens that we can fit. The maximum number of tokens that can be packed can be derived approximately from our previous memory limit static_batch x max_sequence_length. This allows us to pack more instances in one batch without much padding because the sequences would be of similar lengths after sorting.
We can’t sort the entire dataset because machine learning training is based on the assumption that our instances are drawn independently from an identical distribution (IID). If we were to sort the entire dataset this breaks the assumption as our samples are no longer drawn independently from each other. If sentence length were a confounding factor then the model might fit on this spurious correlation.
We have a trade-off here between statistical power derived from randomization of our samples and lesser error in gradient updates derived from larger batch sizes if we batch dynamically.
Generally, we can have a positive trade off by sampling a window of instances and sorting withing the window and forming batches.
The Dataset we implemented above is a map-style dataset. It implements length and random access to each individual data sample with index (__getitem__). The sampling into batches is taken care of a sampler passed to DataLoader.
I don’t think there is a clean way to implement a map-style dataset and a collate function such that we get batches with dynamic batch sizes but same number of tokens per batch. This comes from the basic mismatch of number of dynamic batches which you can form keeps changing based on the larger window you sample.
So it turns out that we have to do all the shuffling, windowing, sorting and batching inside a iterable-style IterableDataset dataset abstraction. These features are implemented by infinibatch.
In large datasets, it’s typical not to wait for an entire epoch to checkpoint your model to recover from failures. So to be able to recover and continue training in a deterministic manner, such that it converges to same state if the failure hadn’t occured, we have to checkpoint the random state that controls the order in which our samples are generated.
Infinibatch is a library of checkpointable iterators for randomized data loading of massive data sets in deep neural network training.
It is aimed at simplify the processing of large datasets. It is a collection of pure python classes that implement __iter__ interface. They can be composed inside one another easily and the final composed iterator can be checkpointed as a single entity.You can checkout it’s basic tutorial here. We will use it to address the listed challenges piece by piece and then finally make it work inside IterableDataset and DataLoader abstractions. We will also see the tricks needed to make it work distributed data parallel training.
Following the infinibatch tutorial, we divide our dataset into multiple gzip chunks of 10000 sentences each.
!mkdir -p wikitext-103-chunks
!split -a 4 --lines 10000 --numeric-suffixes --filter 'gzip > wikitext-103-chunks/$FILE.txt.gz' wikitext-103-raw/wiki.train.raw train.We can now create an iterator using infinibatch with a function that can deserialize a shard. Infinibatch takes care of loading multiple in a shuffled order. We can control the amount of deserialized individual examples from the shards be buffered using buffer_size parameter. The library returns a python iterable. We can call next(iterable) or iterate with a for to get the examples.
Note: Passing train=True creates an infinite iterator that cycles after a full run on the dataset. The chunked_dataset_iterator method returns a composition of iterators, you can refer the source code here
import gzip, glob
from functools import partial
from infinibatch import datasets, iterators
def read_chunk(path):
with open(path, "rb") as fp:
lines = gzip.decompress(fp.read()).decode(encoding='utf-8').splitlines()
lines = [sentence.strip() for sentence in lines if len(sentence.strip()) > 2]
return iter(lines)
sentence_it = datasets.chunked_dataset_iterator(
chunk_refs = glob.glob('wikitext-103-chunks/train.*.txt.gz'),
read_chunk_fn = read_chunk,
buffer_size = 100000, seed = 1337, train=True, shuffle=True)
print(next(sentence_it))In 1993 , David Mirkin hired Scully to write for The Simpsons , as a replacement for the departing Conan O 'Brien , after reading some of his sample scripts . He began as a writer and producer for the show during its fifth season and wrote the episodes " Lisa 's Rival " , " Two Dozen and One Greyhounds " and " Lisa on Ice " which aired in season six . " Lisa 's Rival " was his first episode ; he wrote the script , but the original concept had been conceived by O 'Brien . Similarly , he wrote the script for " Two Dozen and One Greyhounds " , which was based on an idea by Al Jean and Mike Reiss . " Lisa on Ice " was inspired by Scully 's love of ice hockey and featured many experiences from his childhood , as was " Marge Be Not Proud " ( which he wrote for season seven ) which was based " one of the most traumatic moments " of his life , when he was caught shoplifting aged twelve . He jokingly told Variety that " It 's great to be paid for reliving the horrors of your life . " He also wrote " Team Homer " and " Lisa 's Date with Density " . Scully noted : " I wrote a lot of Lisa 's shows . I have five daughters , so I like Lisa a lot . I like Homer , too . Homer comes very naturally to me : I don 't know if that 's a good or a bad thing . A lot of my favorite episodes are the ones when Homer and Lisa are in conflict with each other ... They 're very human , I think that 's their appeal . "We can now compose our tokenizer upon our sentence iterator. Infinibatch has two ways of doing this, 1. MapIterator 2. ParallelMapIterator
If you use pytorch and need multiprocessing to do costly transformations over your data on the fly, use the ParallelMap and set the num_processes with what you would have with num_workers. And set num_workers=0 in your dataloader.
tokenize_fn = partial(tokenizer, max_length=512, truncation=True)
features_it = iterators.ParallelMapIterator(
source_iterator=sentence_it,
num_processes=4,
num_items_per_process=1000,
transform=tokenize_fn
)
next(features_it){'input_ids': [101, 1130, 1949, 117, 1681, 20522, 4314, 4327, 20452, 16125, 1106, 3593, 1111, 1109, 20726, 117, 1112, 170, 5627, 1111, 1103, 18646, 17727, 152, 112, 9620, 117, 1170, 3455, 1199, 1104, 1117, 6876, 15690, 119, 1124, 1310, 1112, 170, 2432, 1105, 2451, 1111, 1103, 1437, 1219, 1157, 3049, 1265, 1105, 1724, 1103, 3426, 107, 6516, 112, 188, 155, 15895, 107, 117, 107, 1960, 2091, 10947, 1105, 1448, 6285, 16930, 1116, 107, 1105, 107, 6516, 1113, 6172, 107, 1134, 4086, 1107, 1265, 1565, 119, 107, 6516, 112, 188, 155, 15895, 107, 1108, 1117, 1148, 2004, 132, 1119, 1724, 1103, 5444, 117, 1133, 1103, 1560, 3400, 1125, 1151, 10187, 1118, 152, 112, 9620, 119, 10321, 117, 1119, 1724, 1103, 5444, 1111, 107, 1960, 2091, 10947, 1105, 1448, 6285, 16930, 1116, 107, 117, 1134, 1108, 1359, 1113, 1126, 1911, 1118, 2586, 2893, 1105, 2639, 11336, 14788, 119, 107, 6516, 1113, 6172, 107, 1108, 3768, 1118, 20452, 16125, 112, 188, 1567, 1104, 2854, 4700, 1105, 2081, 1242, 5758, 1121, 1117, 5153, 117, 1112, 1108, 107, 9751, 2176, 4108, 1753, 5096, 4867, 107, 113, 1134, 1119, 1724, 1111, 1265, 1978, 114, 1134, 1108, 1359, 107, 1141, 1104, 1103, 1211, 23057, 4899, 107, 1104, 1117, 1297, 117, 1165, 1119, 1108, 2347, 4130, 18867, 4079, 4030, 119, 1124, 18114, 1193, 1500, 15526, 1115, 107, 1135, 112, 188, 1632, 1106, 1129, 3004, 1111, 1231, 2646, 3970, 1103, 5367, 1116, 1104, 1240, 1297, 119, 107, 1124, 1145, 1724, 107, 2649, 12353, 107, 1105, 107, 6516, 112, 188, 14265, 1114, 14760, 13730, 107, 119, 20452, 16125, 2382, 131, 107, 146, 1724, 170, 1974, 1104, 6516, 112, 188, 2196, 119, 146, 1138, 1421, 5421, 117, 1177, 146, 1176, 6516, 170, 1974, 119, 146, 1176, 12353, 117, 1315, 119, 12353, 2502, 1304, 8534, 1106, 1143, 131, 146, 1274, 112, 189, 1221, 1191, 1115, 112, 188, 170, 1363, 1137, 170, 2213, 1645, 119, 138, 1974, 1104, 1139, 5095, 3426, 1132, 1103, 3200, 1165, 12353, 1105, 6516, 1132, 1107, 4139, 1114, 1296, 1168, 119, 119, 119, 1220, 112, 1231, 1304, 1769, 117, 146, 1341, 1115, 112, 188, 1147, 5767, 119, 107, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}Now comes the magic of dynamic batching with BucketedReadaheadBatchIterator. Let’s fix the maximum tokens per batch to 32 * 512 = 16384. This iterator allows you to compute dynamic batch size by iteratively applying a user given function over the current longest example (with length computed by user function) in a sorted read_ahead window. This window is sorted and batches are formed by using the user provided batch_size function iteratively.
Say we want 50 tokens per batch. If we set a read ahead window of 6. Assume we fetch six items [a, b, c, d, e, f] in the first read ahead window.
| Sequence id | Length |
|---|---|
| a | 50 |
| b | 30 |
| c | 20 |
| d | 20 |
| e | 30 |
| f | 20 |
First we sort this window with lengths in decreasing order. The sort order is stable. This preserves the shuffling of equal sized elements from previous iterator. So for our example it would be [a, b, e, c, d, f]
Now we can Compute the dynamic batch sizes by applying the function batch_size iteratively till the window is exhausted. Assume our function is lambda longest_instance: 60 // len(longest_instance). Then applying it once we get first longest item a, current batch size will be 60 //50 = 1. The next longest item remaining can be used to calculate the size of the next batch and so on. So we will end up with [a], [b, e], [c, d, f]. Each of them will have 60 tokens.
You can take a look at the code that does this computation here.
tokens_per_batch = 32 * 512
batches_it = iterators.BucketedReadaheadBatchIterator(
source_iterator=features_it,
# read_ahead is the number of items to be read from previous iterator,
# these are sorted and over which dynamic batches are formed.
read_ahead=10000,
# key determines the length used to sort and choose the longest remaining record.
key=lambda example: len(example['input_ids']),
# Determines the dynamic batch size
batch_size=lambda longest_example: tokens_per_batch // len(longest_example['input_ids']),
seed=0
)
dynamic_batch_wo_padding = next(batches_it)
print(f"Dynamic batch size: {len(dynamic_batch_wo_padding)}")
dynamic_batch_wo_padding = next(batches_it)
print(f"Dynamic batch size: {len(dynamic_batch_wo_padding)}")
print(dynamic_batch_wo_padding[:2])Dynamic batch size: 124
Dynamic batch size: 94
[{'input_ids': [101, 1109, 3500, 3039, 13025, 1126, 1903, 1104, 1492, 188, 1204, 121, 137, 119, 137, 8347, 5682, 113, 5787, 137, 119, 137, 125, 4023, 114, 117, 1166, 126, 137, 119, 137, 126, 6549, 113, 123, 137, 119, 137, 126, 4023, 114, 1679, 24773, 1167, 1190, 1147, 7741, 119, 3900, 112, 188, 3039, 4049, 1198, 170, 1423, 24773, 1114, 12936, 6398, 2541, 1107, 1103, 3499, 1526, 2084, 1105, 6625, 2188, 20394, 5773, 1633, 117, 1229, 3500, 1486, 2055, 11142, 117, 1681, 156, 10098, 2897, 1105, 1884, 1775, 4978, 11661, 1862, 119, 3396, 24773, 1116, 117, 1160, 1121, 1296, 2755, 117, 1127, 4410, 1112, 7474, 6635, 1107, 1103, 1886, 131, 3500, 112, 188, 4367, 155, 5792, 1108, 1925, 1229, 141, 119, 6511, 1108, 1237, 117, 1105, 3900, 112, 188, 139, 119, 3160, 1108, 1375, 2170, 1229, 1287, 25730, 1931, 17932, 1121, 1203, 2512, 119, 3500, 112, 188, 3499, 1526, 2084, 11311, 5157, 14618, 1125, 2856, 1471, 1121, 1103, 3039, 1160, 2277, 2988, 1106, 1103, 1886, 1112, 170, 1871, 1104, 170, 2960, 1104, 1532, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}, {'input_ids': [101, 2907, 1107, 1478, 117, 1119, 1125, 170, 4374, 1648, 1107, 1103, 28117, 21643, 1273, 1109, 156, 13622, 22273, 7443, 119, 1230, 1397, 1273, 1648, 1108, 1107, 1823, 20452, 1324, 10781, 1204, 2391, 112, 188, 11826, 6945, 1643, 4371, 113, 1478, 114, 119, 1130, 1103, 1273, 117, 17784, 1733, 19572, 1307, 1126, 1586, 23963, 1233, 117, 1150, 1110, 2802, 1106, 1712, 3542, 1104, 8125, 7782, 7895, 112, 188, 1959, 119, 6945, 1643, 4371, 1108, 12468, 1120, 170, 1957, 8685, 1120, 1103, 13631, 2683, 3506, 1570, 2352, 2263, 1107, 1478, 119, 2711, 1103, 3216, 3761, 117, 1103, 1273, 1108, 170, 2798, 2244, 117, 6957, 109, 22803, 1550, 4529, 117, 1543, 1122, 1117, 2439, 137, 118, 137, 19842, 1273, 1106, 1103, 1322, 1104, 1369, 119, 17784, 1733, 19572, 112, 188, 1397, 2672, 1108, 147, 1813, 3925, 113, 1478, 114, 117, 3714, 4387, 144, 7777, 7836, 2328, 1348, 119, 1109, 2523, 1110, 1359, 1113, 158, 119, 156, 119, 4620, 4140, 156, 12821, 3101, 6944, 112, 188, 1581, 5634, 1414, 14871, 1104, 1103, 1269, 1271, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}]Now we can collate our examples and see how much this scheme has saved us. Since a training iterator is infinite, we will recreate our iterators with a non-infinite iterator.
sentence_it_finite = datasets.chunked_dataset_iterator(
chunk_refs = glob.glob('wikitext-103-chunks/train.*.txt.gz'),
read_chunk_fn = read_chunk,
buffer_size = 100000,
seed = 1337,
train=False,
shuffle=False
)
features_it_finite = iterators.ParallelMapIterator(
source_iterator=sentence_it_finite,
num_processes=4,
num_items_per_process=1000,
transform=tokenize_fn
)
batches_it_finite = iterators.BucketedReadaheadBatchIterator(
source_iterator=features_it_finite,
read_ahead=10000, # Determines the window for the bucket which
# will be sorted and converted to batches.
key=lambda example: len(example['input_ids']), # Determines the length used
# to sort and choose the longest remaining record.
batch_size=lambda longest: tokens_per_batch // len(longest['input_ids']),
# Determines the dynamic batch size
seed=0
)
collate_fn = partial(tokenizer.pad, return_tensors='pt')
tensors_it_finite = iterators.MapIterator(
batches_it_finite,
transform=collate_fn
)total_batches_dynamic = 0
total_tokens_dynamic = 0
padding_tokens_dynamic = 0
batch_lengths_dynamic = []
for batch in tqdm.tqdm(tensors_it_finite):
total_batches_dynamic += 1
batched_input_ids = batch["input_ids"]
batch_lengths_dynamic.append(batched_input_ids.shape[1])
total_tokens_dynamic += batched_input_ids.numel()
padding_tokens_dynamic += batched_input_ids[batched_input_ids == tokenizer.pad_token_id].numel()7650it [08:11, 15.57it/s]print(f"Total Batches : {total_batches_dynamic}") # Seeing the tqdm stats.
print(f"Padding Tokens : {padding_tokens_dynamic}")
print(f"Input Tokens : {total_tokens_dynamic - padding_tokens_dynamic}")
print(f"Total Tokens : {total_tokens_dynamic}")
print(f"Padding Tokens % : {(padding_tokens_dynamic*100)/total_tokens_dynamic}")Total Batches : 7650
Padding Tokens : 3838939
Input Tokens : 119699332
Total Tokens : 123538271
Padding Tokens % : 3.1074896620497463We have reduced the % of padding tokens per epoch from 67% to just around 3%.The total batches needed to process it in the same max tokens per batch limitation hence got reduced nearly five times from 36390 to 7642.
The processing time is just one minute extra. I guess that might be due to IO, but you could try benchmarking that with more rigour.
Now, plotting the length distribution for dynamic batches.
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=[7,5])
n, bins, patches = plt.hist(x=batch_lengths_dynamic, bins=50, color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Batch Sequence Length',fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.title('Dynamic Batch - Dynamic Padding Length Distribution',fontsize=15)
plt.show()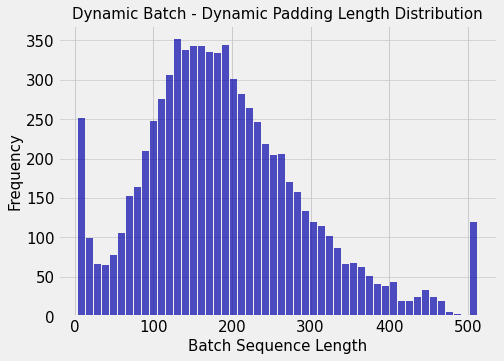
We now see that the expected per batch sequence length has reduced from 300 to 200.
In practise using variable batch sizes could be a problem depending on your task. As tokens in an instance are already correlated, having few instances (though longer) in one batch might give a more noisy gradient update than many shorter instances in a batch. This is my speculation as to why I wasn’t able to make purely dynamic batch sizes work well with a token classification fine-tuning on BERT.
But all is not lost here, we can still use bucketing to have uniform length batches with fewer padding tokens. Let’s checkout the padding tokens % when we fix the batch size as 32 but sort a window of 10 batches (320 instances) and then form batches.
sentence_it_finite = datasets.chunked_dataset_iterator(
chunk_refs = glob.glob('wikitext-103-chunks/train.*.txt.gz'),
read_chunk_fn = read_chunk,
buffer_size = 100000,
seed = 1337,
train=False,
shuffle=False
)
features_it_finite = iterators.ParallelMapIterator(
source_iterator=sentence_it_finite,
num_processes=4,
num_items_per_process=1000,
transform=tokenize_fn
)
batches_it_finite = iterators.BucketedReadaheadBatchIterator(
source_iterator=features_it_finite,
key=lambda example: len(example['input_ids']), # Determines the length used
read_ahead=320, # Setting this ten times the static batch size.
batch_size=32,
seed=0
)
collate_fn = partial(tokenizer.pad, return_tensors='pt')
tensors_it_finite = iterators.MapIterator(
batches_it_finite,
transform=collate_fn
)
total_batches_bucket_sorted = 0
total_tokens_bucket_sorted= 0
padding_tokens_bucket_sorted = 0
batch_lengths_bucket_sorted = []
for batch in tqdm.tqdm(tensors_it_finite):
total_batches_bucket_sorted += 1
batched_input_ids = batch["input_ids"]
batch_lengths_bucket_sorted.append(batched_input_ids.shape[1])
total_tokens_bucket_sorted += batched_input_ids.numel()
padding_tokens_bucket_sorted += batched_input_ids[batched_input_ids == tokenizer.pad_token_id].numel()
print(f"\nTotal Batches : {total_batches_bucket_sorted}") # Seeing the tqdm stats.
print(f"Padding Tokens : {padding_tokens_bucket_sorted}")
print(f"Input Tokens : {total_tokens_bucket_sorted - padding_tokens_bucket_sorted}")
print(f"Total Tokens : {total_tokens_bucket_sorted}")
print(f"Padding Tokens % : {(padding_tokens_bucket_sorted*100)/total_tokens_bucket_sorted}")36390it [08:26, 71.81it/s]
Total Batches : 36390
Padding Tokens : 31806252
Input Tokens : 119699332
Total Tokens : 151505584
Padding Tokens % : 20.993451964120347So we see that the % of total padding tokens has decreased from 67% to 20%. And we can see from the below the distribution of sequence length of batches is close to the distribution of individual sequence lengths. This is different from the case where we made static batches without sorting.
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=[7,5])
n, bins, patches = plt.hist(x=batch_lengths_bucket_sorted, bins=50, color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Batch Sequence Length',fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.ylabel('Frequency',fontsize=15)
plt.title('Window Sorted Static Batching + Dynamic Padding Length Distribution',fontsize=15)
plt.show()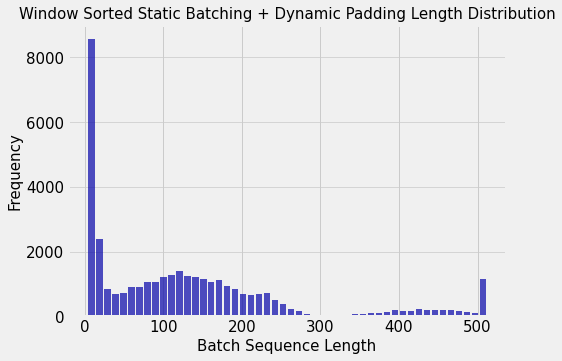
One cool feature of infinibatch is that you can checkpoint a particular state in which the composed iterators is at and restore (rewind?) it back to that state. This is very cool considering it works recursively on the composed iterators and even on infinite iterator. Let’s recreate our iterators and check this out.
sentence_it = datasets.chunked_dataset_iterator(
chunk_refs = glob.glob('wikitext-103-chunks/train.*.txt.gz'),
read_chunk_fn = read_chunk,
buffer_size = 100000,
seed = 1337,
train=False,
shuffle=False
)
features_it = iterators.ParallelMapIterator(
source_iterator=sentence_it,
num_processes=4,
num_items_per_process=1000,
transform=tokenize_fn
)
batches_it = iterators.BucketedReadaheadBatchIterator(
source_iterator=features_it,
read_ahead=10000, # Determines the window for the bucket which
# will be sorted and converted to batches.
key=lambda example: len(example['input_ids']), # Determines the length used
# to sort and choose the longest remaining record.
batch_size=lambda longest: tokens_per_batch // len(longest['input_ids']),
# Determines the dynamic batch size
seed=0
)
collate_fn = partial(tokenizer.pad, return_tensors='pt')
tensors_it = iterators.MapIterator(
batches_it,
transform=collate_fn
)initial_state = tensors_it.getstate()
print("Initial State of composed iterators", initial_state)
# Draw 5 batches
batches = [next(tensors_it) for _ in range(5)]
print(f"Current State after sampling 5 batches: {tensors_it.getstate()}")
# Reset the Iterator
tensors_it.setstate(initial_state)
# Redraw 5 batches
redraw_batches = [next(tensors_it) for _ in range(5)]
print(f"State after resampling 5 batches: {tensors_it.getstate()}")
# Check equal
all_equal = True
for b1, b2 in zip(batches, redraw_batches):
for k in b1:
if torch.all(b1[k].eq(b2[k])):
continue
all_equal = False
break
if not all_equal:
break
print(f"All items drawn after resetting are equal: {all_equal}")Initial State of composed iterators {'source_state': None, 'random_state': None, 'num_served': 0}
Current State after sampling 5 batches: {'source_state': {'source_state': None, 'flattened_items_yielded': 0}, 'random_state': (3, (2147483648, 766982754, 497961170, 3952298588, 2331775348, 1811986599, 3100132149, 3188119873, 3937547222, 215718963, 3315684082, 2978012849, 2428261856, 1298227695, 1704729580, 54668373, 3285201915, 3285178464, 1552935063, 988471319, 3135387943, 1691402966, 2757551880, 416056905, 907387413, 1072924981, 33903495, 2168419592, 2429050353, 831159753, 430343641, 3315943586, 1761671042, 864453023, 334804929, 1627478028, 2596811275, 3468733638, 3994375553, 1457139722, 3139722021, 1334790738, 2656639915, 3535811098, 1464315470, 2397423927, 885719490, 1140895889, 3284299483, 2854516462, 2734973817, 147484763, 792049954, 114360641, 3345458839, 1159898878, 1410498733, 2242989638, 453922141, 1344019764, 413870456, 3089405849, 1494382840, 470157779, 4266372830, 2831181573, 1361928602, 1589253513, 1381373062, 753045124, 987032420, 781978839, 2953638767, 3258570111, 3006718191, 1675218601, 1854232715, 3655829819, 1731242722, 2192104666, 1736665161, 740150002, 1195833394, 1610203160, 159492766, 4041488705, 3128952632, 2867295744, 3272632449, 886824304, 1791482600, 221114776, 3867175393, 4020804062, 1077871826, 1298953503, 996366221, 4149754679, 2483052703, 2615558283, 274318093, 1716359450, 4099129961, 1026774175, 288240973, 1459347562, 2365566296, 3690105224, 3065780221, 2050634722, 2652606621, 3185241207, 3026457375, 3456165734, 1880121515, 3398461093, 1795638629, 2379692076, 608668379, 1261955525, 84456522, 1913485156, 106878280, 757183891, 2913957588, 160418091, 2025664758, 141497907, 1657818026, 3053760160, 672193054, 4157546743, 223046484, 1623470498, 1201972930, 675008814, 684162366, 1738776330, 3025656654, 159760723, 1908867305, 3933381342, 2545706671, 467196949, 1427819885, 842150314, 4032903454, 2140851898, 3269883445, 975813755, 4177392955, 1556690684, 2535611513, 462962732, 67591358, 1729610528, 2025206740, 3153739740, 3255032049, 4186226368, 1070144624, 3107867195, 1621006038, 63742485, 835629717, 3189842019, 3950227584, 3184714559, 841836938, 1685394870, 657939920, 766156242, 1412314179, 1048281639, 4037161120, 2044490307, 1923947830, 3900790422, 907554295, 276417304, 860658646, 3574201134, 3508771399, 2110232300, 1636296241, 1405006077, 1093408401, 3243057343, 1519791182, 1994660136, 3829840937, 2644974199, 957955566, 3487641161, 1646922510, 1907939989, 3836029453, 3429168778, 201307778, 72550089, 2464394982, 1695794191, 3344785682, 996786130, 3589457196, 1241754792, 1291082245, 4224603667, 1194379475, 2693491244, 881186965, 2705535111, 445306946, 440274268, 1980827733, 2482488861, 3205215943, 2119332222, 2928713046, 1418736938, 652581136, 2474070665, 2208621536, 4171251876, 2303664214, 443762656, 2981912989, 2199228311, 2652261633, 3166738494, 3443009210, 3498764432, 424010848, 4065487566, 2262993542, 1756076712, 1477098233, 2742171915, 306185806, 3610666541, 923091830, 1034267993, 2336668648, 1880719718, 676878038, 3788797208, 3763351494, 3985428106, 1101865631, 1130501258, 3672967388, 3432003530, 4124438011, 1660392285, 4025484827, 2108074566, 3815409682, 42955331, 3248965569, 1643835718, 1246665668, 1071162194, 3814069229, 115491158, 985096811, 3311029186, 2990827378, 3101633320, 1648574497, 1470117052, 174145027, 2019894819, 2035501481, 459104123, 3507464599, 2093352659, 3369174406, 618767835, 4009895756, 935587447, 3956987426, 33753995, 307782427, 2473424805, 1440371818, 2382619594, 2138695812, 3164510238, 1318650933, 2910086616, 3886677510, 566832801, 3718063320, 1559818704, 183047272, 1142362855, 26306548, 645536402, 3875596208, 2272778168, 3512733409, 1897046338, 38248886, 2570759766, 1806313150, 860304898, 2433450338, 4124013408, 1216634590, 1275388896, 1169566669, 652504502, 761221427, 1448403764, 3129135949, 2513214949, 1269533687, 2413509541, 1226750363, 2450740925, 4094137910, 945759293, 3636927736, 3178020081, 2509964157, 3878869300, 1848504895, 2018369720, 1579755740, 1023627943, 924838836, 2653160914, 1812804174, 1521323076, 4012390528, 1338763317, 2608655937, 16022784, 1672945066, 2177189646, 2944458483, 2213810972, 1369873847, 1224017670, 130901785, 3595066712, 2259115284, 3316038259, 455873927, 2917250465, 3599550610, 1502173758, 684943436, 3079863840, 3144992244, 942855823, 1771140188, 2118780653, 3411494225, 2711180217, 4239611184, 1371891067, 3398566397, 3105518599, 1310665701, 3345178451, 2959821156, 242241789, 2148966880, 3192740583, 404401893, 3605380577, 1446464038, 3920522056, 2577523013, 1079274576, 286634372, 1752710796, 2351075979, 981312309, 3410516352, 3468455736, 1938779182, 1592494371, 1533303080, 88045436, 438252489, 1220512168, 3487004938, 3724852871, 1073434882, 3728218947, 2977555283, 4105408406, 3553772656, 1462006821, 3917158017, 119003006, 3470530198, 3439192457, 2829375771, 3555715155, 32324691, 588735808, 1459221702, 803072782, 2699519868, 1530797005, 79738580, 671990400, 4289511388, 3207115447, 2584684068, 832698998, 760958416, 1217440464, 2517898131, 2418819938, 3629956222, 3445024962, 206619378, 365007395, 522114139, 1707954431, 540423623, 1786750801, 369253262, 4239016754, 147889201, 1637777773, 236798285, 2806120188, 586972608, 2201782716, 1323327827, 819485723, 406078680, 3407345698, 1537169369, 1821691865, 527271655, 3751827102, 1465426495, 3321682429, 2179672664, 401355478, 1068871880, 24609462, 1403522408, 2311580015, 1532058170, 3877815340, 1768430711, 1619755157, 2832904331, 475102697, 354987331, 3295386430, 2816873951, 1039415736, 363972779, 1499307670, 2895506264, 3746345349, 2678027234, 3251899088, 955392878, 2329157295, 1343358773, 309573887, 2410178377, 2843173466, 361132917, 1755816798, 1319204283, 609284796, 1998842567, 1892325921, 223190385, 1483015769, 2876023365, 3876009312, 3199738344, 491524099, 160383137, 1219178873, 3870310498, 1114580266, 4279604166, 855339774, 1983818547, 2297848784, 4118592947, 4084409863, 2225095054, 4215601993, 946447434, 4205503762, 146088676, 778046685, 1876936928, 3157333726, 2173097090, 3215738813, 4135448234, 1219619643, 1936128689, 2897130162, 3336043946, 3779039524, 4200886837, 1359380925, 3402593091, 3140713935, 50855190, 3122065768, 1501584468, 2512255124, 687125154, 2666013386, 837819715, 3057258172, 3653455791, 2868624990, 322131992, 42534870, 4036564806, 798099710, 3533853670, 190914037, 3726947981, 2601169403, 602059656, 1365668439, 1918780004, 394790500, 277566007, 3891847777, 3365421094, 3139612253, 1380519090, 1183088424, 4203794803, 3049949521, 4214159484, 3446206962, 1875544460, 3207220027, 3288287026, 913535288, 178159620, 1410694581, 4190575040, 880731713, 1427805121, 404869072, 3413191414, 2865934056, 2899472677, 4239222733, 688404529, 3923323887, 933651074, 1199453686, 642723732, 2850614853, 3104368451, 3054041024, 3129913503, 2805843726, 1829781129, 3479062313, 650272704, 4224852052, 4085038685, 2616580676, 1793860711, 585126334, 2995262791, 520446536, 3855655015, 1571815563, 2240778227, 2051010344, 1694977983, 788402852, 1988089041, 2035558649, 1800063056, 1234412692, 2490862867, 417320514, 2415019489, 3374117797, 136034611, 898704236, 1247106941, 3923519397, 3563607190, 2454738671, 3522360389, 2672645476, 146828884, 3985140042, 4233949333, 1184742586, 860278824, 2815489967, 983483427, 3190081845, 3288865305, 3575181235, 1292151129, 4007823805, 4049420597, 3499391972, 1611182906, 1721268432, 2944249577, 2487212557, 789127738, 4027610014, 1057334138, 2902720905, 624), None), 'num_served': 5}
State after resampling 5 batches: {'source_state': {'source_state': None, 'flattened_items_yielded': 0}, 'random_state': (3, (2147483648, 766982754, 497961170, 3952298588, 2331775348, 1811986599, 3100132149, 3188119873, 3937547222, 215718963, 3315684082, 2978012849, 2428261856, 1298227695, 1704729580, 54668373, 3285201915, 3285178464, 1552935063, 988471319, 3135387943, 1691402966, 2757551880, 416056905, 907387413, 1072924981, 33903495, 2168419592, 2429050353, 831159753, 430343641, 3315943586, 1761671042, 864453023, 334804929, 1627478028, 2596811275, 3468733638, 3994375553, 1457139722, 3139722021, 1334790738, 2656639915, 3535811098, 1464315470, 2397423927, 885719490, 1140895889, 3284299483, 2854516462, 2734973817, 147484763, 792049954, 114360641, 3345458839, 1159898878, 1410498733, 2242989638, 453922141, 1344019764, 413870456, 3089405849, 1494382840, 470157779, 4266372830, 2831181573, 1361928602, 1589253513, 1381373062, 753045124, 987032420, 781978839, 2953638767, 3258570111, 3006718191, 1675218601, 1854232715, 3655829819, 1731242722, 2192104666, 1736665161, 740150002, 1195833394, 1610203160, 159492766, 4041488705, 3128952632, 2867295744, 3272632449, 886824304, 1791482600, 221114776, 3867175393, 4020804062, 1077871826, 1298953503, 996366221, 4149754679, 2483052703, 2615558283, 274318093, 1716359450, 4099129961, 1026774175, 288240973, 1459347562, 2365566296, 3690105224, 3065780221, 2050634722, 2652606621, 3185241207, 3026457375, 3456165734, 1880121515, 3398461093, 1795638629, 2379692076, 608668379, 1261955525, 84456522, 1913485156, 106878280, 757183891, 2913957588, 160418091, 2025664758, 141497907, 1657818026, 3053760160, 672193054, 4157546743, 223046484, 1623470498, 1201972930, 675008814, 684162366, 1738776330, 3025656654, 159760723, 1908867305, 3933381342, 2545706671, 467196949, 1427819885, 842150314, 4032903454, 2140851898, 3269883445, 975813755, 4177392955, 1556690684, 2535611513, 462962732, 67591358, 1729610528, 2025206740, 3153739740, 3255032049, 4186226368, 1070144624, 3107867195, 1621006038, 63742485, 835629717, 3189842019, 3950227584, 3184714559, 841836938, 1685394870, 657939920, 766156242, 1412314179, 1048281639, 4037161120, 2044490307, 1923947830, 3900790422, 907554295, 276417304, 860658646, 3574201134, 3508771399, 2110232300, 1636296241, 1405006077, 1093408401, 3243057343, 1519791182, 1994660136, 3829840937, 2644974199, 957955566, 3487641161, 1646922510, 1907939989, 3836029453, 3429168778, 201307778, 72550089, 2464394982, 1695794191, 3344785682, 996786130, 3589457196, 1241754792, 1291082245, 4224603667, 1194379475, 2693491244, 881186965, 2705535111, 445306946, 440274268, 1980827733, 2482488861, 3205215943, 2119332222, 2928713046, 1418736938, 652581136, 2474070665, 2208621536, 4171251876, 2303664214, 443762656, 2981912989, 2199228311, 2652261633, 3166738494, 3443009210, 3498764432, 424010848, 4065487566, 2262993542, 1756076712, 1477098233, 2742171915, 306185806, 3610666541, 923091830, 1034267993, 2336668648, 1880719718, 676878038, 3788797208, 3763351494, 3985428106, 1101865631, 1130501258, 3672967388, 3432003530, 4124438011, 1660392285, 4025484827, 2108074566, 3815409682, 42955331, 3248965569, 1643835718, 1246665668, 1071162194, 3814069229, 115491158, 985096811, 3311029186, 2990827378, 3101633320, 1648574497, 1470117052, 174145027, 2019894819, 2035501481, 459104123, 3507464599, 2093352659, 3369174406, 618767835, 4009895756, 935587447, 3956987426, 33753995, 307782427, 2473424805, 1440371818, 2382619594, 2138695812, 3164510238, 1318650933, 2910086616, 3886677510, 566832801, 3718063320, 1559818704, 183047272, 1142362855, 26306548, 645536402, 3875596208, 2272778168, 3512733409, 1897046338, 38248886, 2570759766, 1806313150, 860304898, 2433450338, 4124013408, 1216634590, 1275388896, 1169566669, 652504502, 761221427, 1448403764, 3129135949, 2513214949, 1269533687, 2413509541, 1226750363, 2450740925, 4094137910, 945759293, 3636927736, 3178020081, 2509964157, 3878869300, 1848504895, 2018369720, 1579755740, 1023627943, 924838836, 2653160914, 1812804174, 1521323076, 4012390528, 1338763317, 2608655937, 16022784, 1672945066, 2177189646, 2944458483, 2213810972, 1369873847, 1224017670, 130901785, 3595066712, 2259115284, 3316038259, 455873927, 2917250465, 3599550610, 1502173758, 684943436, 3079863840, 3144992244, 942855823, 1771140188, 2118780653, 3411494225, 2711180217, 4239611184, 1371891067, 3398566397, 3105518599, 1310665701, 3345178451, 2959821156, 242241789, 2148966880, 3192740583, 404401893, 3605380577, 1446464038, 3920522056, 2577523013, 1079274576, 286634372, 1752710796, 2351075979, 981312309, 3410516352, 3468455736, 1938779182, 1592494371, 1533303080, 88045436, 438252489, 1220512168, 3487004938, 3724852871, 1073434882, 3728218947, 2977555283, 4105408406, 3553772656, 1462006821, 3917158017, 119003006, 3470530198, 3439192457, 2829375771, 3555715155, 32324691, 588735808, 1459221702, 803072782, 2699519868, 1530797005, 79738580, 671990400, 4289511388, 3207115447, 2584684068, 832698998, 760958416, 1217440464, 2517898131, 2418819938, 3629956222, 3445024962, 206619378, 365007395, 522114139, 1707954431, 540423623, 1786750801, 369253262, 4239016754, 147889201, 1637777773, 236798285, 2806120188, 586972608, 2201782716, 1323327827, 819485723, 406078680, 3407345698, 1537169369, 1821691865, 527271655, 3751827102, 1465426495, 3321682429, 2179672664, 401355478, 1068871880, 24609462, 1403522408, 2311580015, 1532058170, 3877815340, 1768430711, 1619755157, 2832904331, 475102697, 354987331, 3295386430, 2816873951, 1039415736, 363972779, 1499307670, 2895506264, 3746345349, 2678027234, 3251899088, 955392878, 2329157295, 1343358773, 309573887, 2410178377, 2843173466, 361132917, 1755816798, 1319204283, 609284796, 1998842567, 1892325921, 223190385, 1483015769, 2876023365, 3876009312, 3199738344, 491524099, 160383137, 1219178873, 3870310498, 1114580266, 4279604166, 855339774, 1983818547, 2297848784, 4118592947, 4084409863, 2225095054, 4215601993, 946447434, 4205503762, 146088676, 778046685, 1876936928, 3157333726, 2173097090, 3215738813, 4135448234, 1219619643, 1936128689, 2897130162, 3336043946, 3779039524, 4200886837, 1359380925, 3402593091, 3140713935, 50855190, 3122065768, 1501584468, 2512255124, 687125154, 2666013386, 837819715, 3057258172, 3653455791, 2868624990, 322131992, 42534870, 4036564806, 798099710, 3533853670, 190914037, 3726947981, 2601169403, 602059656, 1365668439, 1918780004, 394790500, 277566007, 3891847777, 3365421094, 3139612253, 1380519090, 1183088424, 4203794803, 3049949521, 4214159484, 3446206962, 1875544460, 3207220027, 3288287026, 913535288, 178159620, 1410694581, 4190575040, 880731713, 1427805121, 404869072, 3413191414, 2865934056, 2899472677, 4239222733, 688404529, 3923323887, 933651074, 1199453686, 642723732, 2850614853, 3104368451, 3054041024, 3129913503, 2805843726, 1829781129, 3479062313, 650272704, 4224852052, 4085038685, 2616580676, 1793860711, 585126334, 2995262791, 520446536, 3855655015, 1571815563, 2240778227, 2051010344, 1694977983, 788402852, 1988089041, 2035558649, 1800063056, 1234412692, 2490862867, 417320514, 2415019489, 3374117797, 136034611, 898704236, 1247106941, 3923519397, 3563607190, 2454738671, 3522360389, 2672645476, 146828884, 3985140042, 4233949333, 1184742586, 860278824, 2815489967, 983483427, 3190081845, 3288865305, 3575181235, 1292151129, 4007823805, 4049420597, 3499391972, 1611182906, 1721268432, 2944249577, 2487212557, 789127738, 4027610014, 1057334138, 2902720905, 624), None), 'num_served': 5}
All items drawn after resetting are equal: TrueSince the state of the iterator is just a dictionary, you can serialize it along with your model weights and restore them to continue training from exact point where you have checkpointed it.
Infinibatch by its very nature can be used only with IterableDataset. The training iterator with shuffling is infinite, so you must limit the training batches to some n steps if you want to maintain the notion of “epochs” to start validation. Or you can eschew whole notion of epochs by validating every nth step or both.
The multi processing workers of DataLoader should be set to zero, with num_workers=0. Rather use ParallelMapIterator to parallelize your pre-processing.
While using IterableDataset in the typical multi-gpu DistributedDataParallel (ddp) setup, you should pass instance_rank and num_instances to have different slices of data distributed to different training devices.
When using finite iterators with ddp for validation set, if you split the data using instance_rank option, the validation can get stuck.This can happen either when your dataset is not divisible by number of ddp processes or doing dynamic batching caused an uneven number of batches produced for each instance. So it’s better to do the validation in one GPU setting instance_rank=0. This is a quick hack, if you find a better option please let me know in the comments.
from torch.utils.data import IterableDataset
import torch.distributed as dist
class IterableCheckpointedDataset(IterableDataset):
"""
Wraps a CheckpointableIterator into a PyTorch IterableDataset, which is
recognized by its type by PyTorch's DataLoader class.
"""
def __init__(self, source: iterators.CheckpointableIterator,
should_reset: bool):
super().__init__()
self._source = source
self._source_state = source.getstate()
self._should_reset = should_reset
def __iter__(self): # this is called in the forked clone
worker_info = torch.utils.data.get_worker_info()
assert (
worker_info is None or worker_info.num_workers == 1
) # not supported since we can't get at the checkpoint for each worker
if self._should_reset:
# For training, since it's infinite iterator, if we train for
# `n` batches with total instances less than dataset size
# it's better not to reset the iterator by itself will cycle back
# with a new shuffle order when all the instances are iterated once.
self._source.setstate(self._source_state)
return self._source
def create_wiki_dataloader(chunks_glob: str,
tokenizer: PreTrainedTokenizerFast,
is_train: bool,
max_seq_len: int = 512,
tokens_per_batch: int = 2 ** 16,
num_workers: int = 4,
buffer_size: int = 100000,
seed: int = 1337) -> DataLoader:
num_instances = 1
instance_rank = 0
if dist.is_available() and is_train:
# Only in training mode we want the data to be split.
# This is a hack to make dynamic batched iterators work while using ddp.
# If we were to split the data and number of batches turned out uneven, then
# Iterator might exhaust early in one GPU leaving it stuck there forever.
# So we rather choose to do the same validation in all the GPUs.
try:
num_instances = dist.get_world_size()
instance_rank = dist.get_rank()
except AssertionError:
pass
sentence_it = datasets.chunked_dataset_iterator(
chunk_refs = glob.glob(chunks_glob),
read_chunk_fn = read_chunk,
buffer_size = buffer_size,
seed = seed,
num_instances=num_instances,
instance_rank=instance_rank,
train=is_train,
shuffle=is_train # Shuffle Only on Train
)
tokenize_fn = partial(tokenizer, max_length=max_seq_len, truncation=True)
features_it = iterators.ParallelMapIterator(
source_iterator=sentence_it,
num_processes=num_workers,
num_items_per_process=1000,
transform=tokenize_fn
)
batches_it = iterators.BucketedReadaheadBatchIterator(
source_iterator=features_it,
read_ahead=10000,
key=lambda example: len(example['input_ids']),
batch_size=lambda longest: tokens_per_batch // len(longest['input_ids']),
seed=seed
)
collate_fn = partial(tokenizer.pad, return_tensors='pt')
tensors_it = iterators.MapIterator(
batches_it,
transform=collate_fn
)
dataset = IterableCheckpointedDataset(
source=tensors_it,
should_reset=not is_train #Reset only for validation
)
return DataLoader(dataset,
# Very important to set this to 0.
num_workers=0,
# Important as we have already batched.
batch_size=1,
# Since batch has only one member which has all the
#tensors already collated, we just return it.
collate_fn=lambda x: x[0]
)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=True)
train_loader = create_wiki_dataloader('wikitext-103-chunks/train.*.txt.gz',
tokenizer=tokenizer,
is_train=True)
val_loader = create_wiki_dataloader('wikitext-103-chunks/train.*.txt.gz',
tokenizer=tokenizer,
is_train=False)
#print(next(iter(train_loader)))
#print(next(iter(val_loader)))